[2021.03.24] 인턴 + 23 CSV 데이터 -> kibana 사용(실습)
-> test용. csv 파일이다.
* 파일의 출처는 www.data.go.kr/
우선, 실습에 있어서 각 서버(elasticsearch, kibana)를 (관리자 권한) 명령 프롬포트로 열어줘야 한다.
C:\ElasticSearch\elasticsearch-7.11.2\bin>elasticsearch.bat
-> elasticsearch 실행
C:\ElasticSearch\kibana-7.11.2-windows-x86_64\bin>kibana.bat
-> kibana 실행
-------------------------------------------------------------------------------------------------------------------------------
C:\ElasticSearch\logstash-7.11.2\bin>logstash -f 파일명.conf
-> 이거는, 위에 2개를 연 후, MySQL에 있는 데이터 -> logstash로 이동할 때 사용(즉, kibana에 서버 연동)
=> 각 실행 파일들은 bin 폴더 안에 있는. bat이다.
-------------------------------------------------------------------------------------------------------------------------------
MySQL 실행하기(프로그램)
-> MySQL 8.0 Command Line Client
-> password 입력하면, 바로 MySQL에 들어가 짐
MySQL 명령어
데이터베이스(스키마) 삭제하는 방법
-> drop database 스키마명
테이블 삭제 방법
mysql> drop table jobschema.abc;
Query OK, 0 rows affected (0.03 sec)
-> drop table 테이블명(jobschema.abc)
-> 스키마 아래에 있는 테이블이므로 jobschema.abc가 됨
데이터베이스(스키마) 보는 방법
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| commerce |
| information_schema |
| jobschema |
| mysql |
| performance_schema |
| sakila |
| sys |
| world |
+--------------------+
8 rows in set (0.01 sec)
데이터베이스 사용(선택)하기
mysql> use jobschema;
Database changed
선택한 데이터베이스 안에 테이블 보기
mysql> show tables;
+---------------------+
| Tables_in_jobschema |
+---------------------+
| test |
+---------------------+
1 row in set (0.00 sec)
해당 테이블 전체 내용(*) 보기
selcet * from 테이블명
MySQL 내용 지우기
-> system clear
-------------------------------------------------------------------------------------------------------------------------------
자, 이제 파일명.conf를 수정해서, logstash와 mysql연동을 해보자.
직전에, 올린 자료와 다르게 데이터를 필터 하여, 예쁘게 가공하는 작업을 해 볼 것이다.
직전 게시글에 사용되었던, 파일명:mysql.conf 이다. 파일 안의 내용을 살펴보자
input {
jdbc {
clean_run => true
jdbc_driver_library => "C:\ElasticSearch\mysql-connector-java-8.0.23\mysql-connector-java-8.0.23.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/jobschema"
jdbc_user => "root"
jdbc_password => "1234"
schedule => "* * * * *"
statement => "select jobid, jobname, executiontime, jobstatus from logstashplugin WHERE jobid > :sql_last_value"
use_column_value => true
tracking_column => "jobid"
}
}
output{
elasticsearch {
hosts => ["localhost:9200"]
index => "logstashmysql"
}
stdout {
codec => rubydebug
}
}
---------------------------------------------------------------------------------------------------------------
자, 이제 오늘 실습으로 사용하기 위해 조금 수정한 test.conf 파일 안의 내용을 살펴보자
위에서 사용되었던, mysql.conf랑 차이가 난다. 또한, # 는 주석처리로 설명해주기 위해 적어놨다.
input {
jdbc {
#(고정) true -> 1970년 1월 1일(또는0)부터 시작 (마지막 칼럼 값 기록 여부)
clean_run => true
# JDBC 파일 위치 경로
jdbc_driver_library => "C:\ElasticSearch\mysql-connector-java-8.0.23\mysql-connector-java-8.0.23.jar"
#(고정)
jdbc_driver_class => "com.mysql.jdbc.Driver"
# "jdbc:mysql://데이터베이스 호스트 주소/데이터베이스(스키마)”
jdbc_connection_string => "jdbc:mysql://localhost:3306/jobschema"
jdbc_user => "root"
jdbc_password => "1234"
#(고정) 매분,매시,매초 등 실행
schedule => "* * * * *"
# (쿼리) sql_last_value는 마지막 값까지 가져오게 sql 작성하면 되는데, 잘 몰라서 속성 첫 번째 칼럼 값으로 가져옴(첫 번째 해도 다 정상출력)
statement => "select * from test WHERE Base_year_month > :sql_last_value ORDER BY Base_year_month"
# 바로 앞에서 정한 statement에서 WHERE Base_year_month > :sql_last_value로 지정했기 때문에
# tracking_column에서도 Base_year_month로 세팅
tracking_column => "Base_year_month"
# true -> 숫자, false -> @timestamp 사용
use_column_value => true
}
}
output{
elasticsearch {
hosts => ["localhost:9200"]
index => "test"
}
stdout {
codec => rubydebug
}
}

자, 여기서 test.conf를 logstash와 MySQL연동을 한 결과 값이다.
하지만 @timestamp와 @version이라는 필요 없는 값이 나온다.
이것을 파일명.conf에서 필터를 통하여 삭제해보자.
필요하지 않은 데이터는 ffilter -> mutate -> remove_field를 사용하여 제거할 수 있다
filter {
mutate {
remove_field => ["@timestamp","@version","host","message"]
}
}
--------------------------------------------------------------------------------------------------------
(최종본) filename: test.conf 이다.(결과 값에 필요 없는 데이터까지 삭제 OK)
input {
jdbc {
#(고정) 마지막 칼럼 값 기록 여부, true시 0 또는 1970년 1월1일부터 시작
clean_run => true
# JDBC 파일 위치 경로
jdbc_driver_library => "C:\ElasticSearch\mysql-connector-java-8.0.23\mysql-connector-java-8.0.23.jar"
#(고정)
jdbc_driver_class => "com.mysql.jdbc.Driver"
# "jdbc:mysql://데이터베이스 호스트 주소/데이터베이스(스키마)”
jdbc_connection_string => "jdbc:mysql://localhost:3306/jobschema"
jdbc_user => "root"
jdbc_password => "1234"
#(고정) 매분,매시,매초 등 실행
schedule => "* * * * *"
# (쿼리) sql_last_value는 마지막 레코드 중 설정된 필드 값(기본값 시간)
# sql_last_value 사용해서 마지막 값만 가져올 수 있도록 SQL 명령어 짜기
statement => "select * from test WHERE Base_year_month > :sql_last_value ORDER BY Base_year_month"
# false 타임스탬프 사용, true 숫자 사용
use_column_value => true
tracking_column => "Base_year_month"
}
}
# 결과 값 출력 시 불필요한 데이터 삭제, @version 뒤에 지우고 싶은 데이터 값을 넣으면 삭제 가능
filter {
mutate {
remove_field => ["@timestamp","@version"]
}
}
output{
elasticsearch {
hosts => ["localhost:9200"]
index => "test1"
}
stdout {
codec => rubydebug
}
}
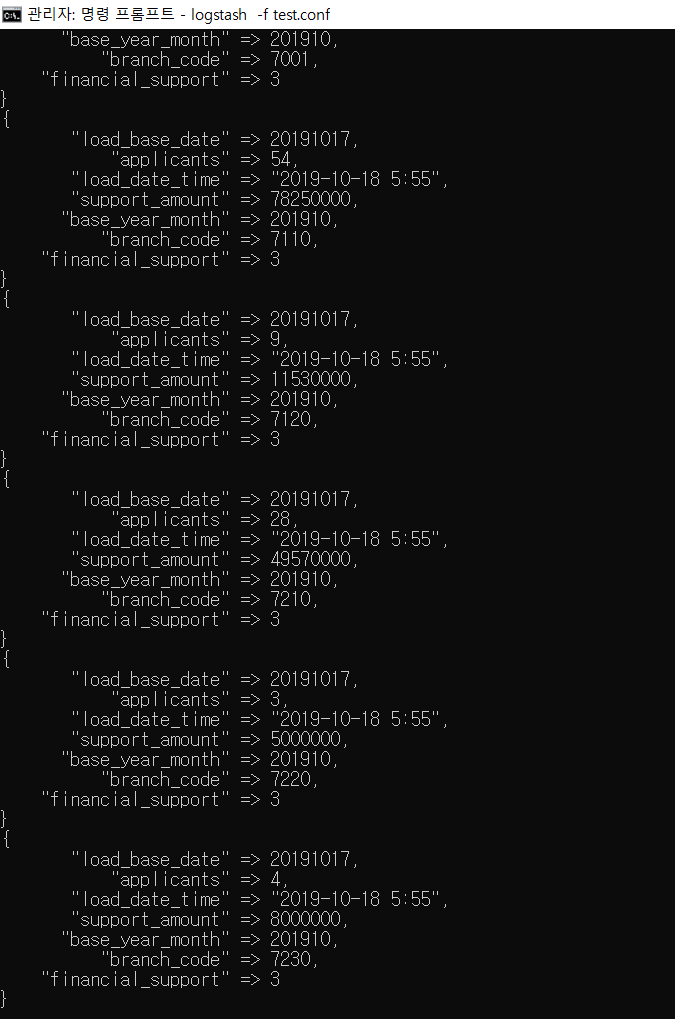
-> 위와 달리 결과 값에서 필요 없는 데이터(@timestamp, @version)가 삭제된 것을 볼 수 있다.
-----------------------------------------------------------------------------------------------------------------------------------
이제, kibana로 들어가서, 분석 및 시각화를 해보자
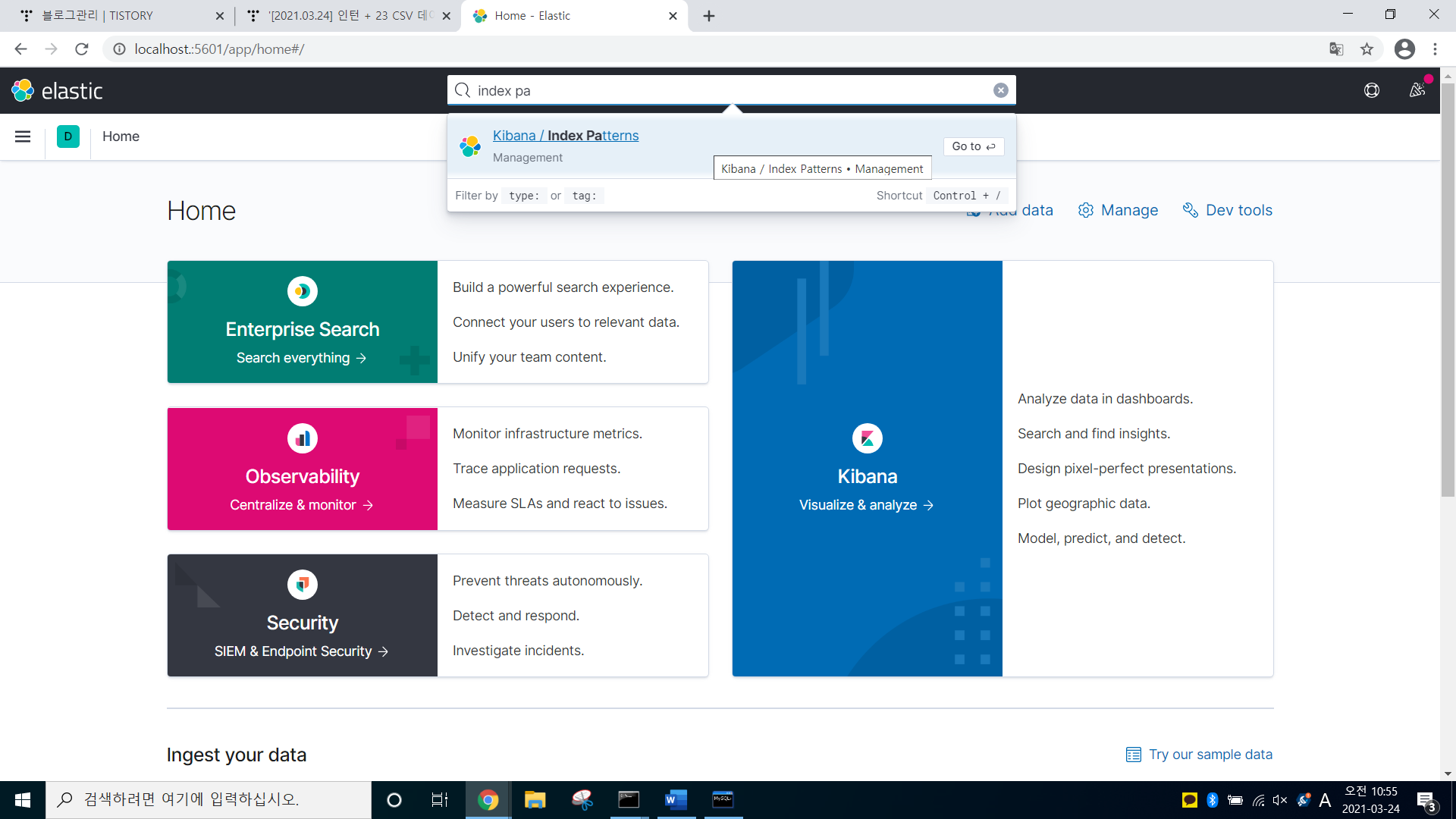
-> http://localhost.:5601 -> search에 index pattens입력
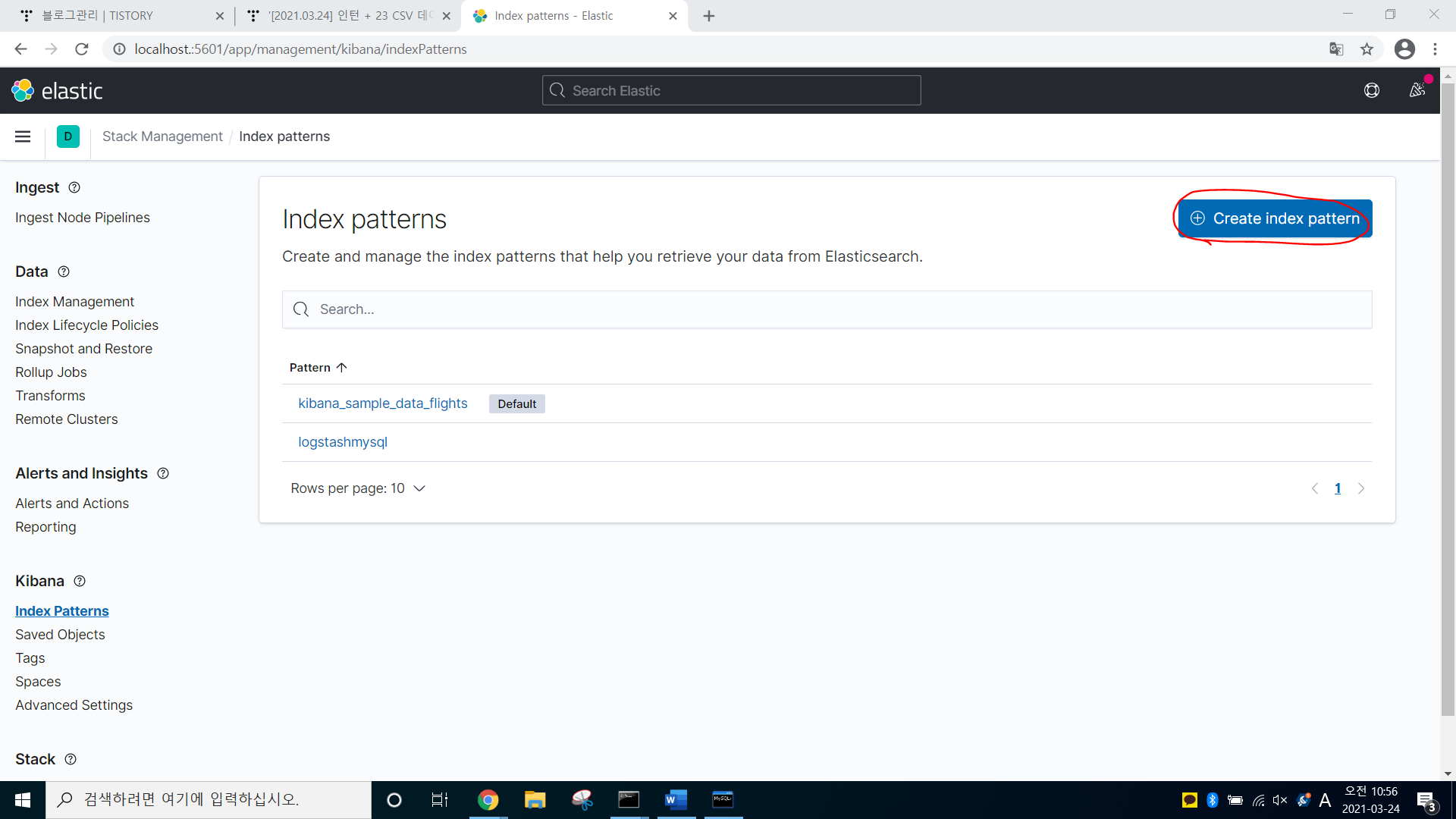
-> Create index patten 클릭
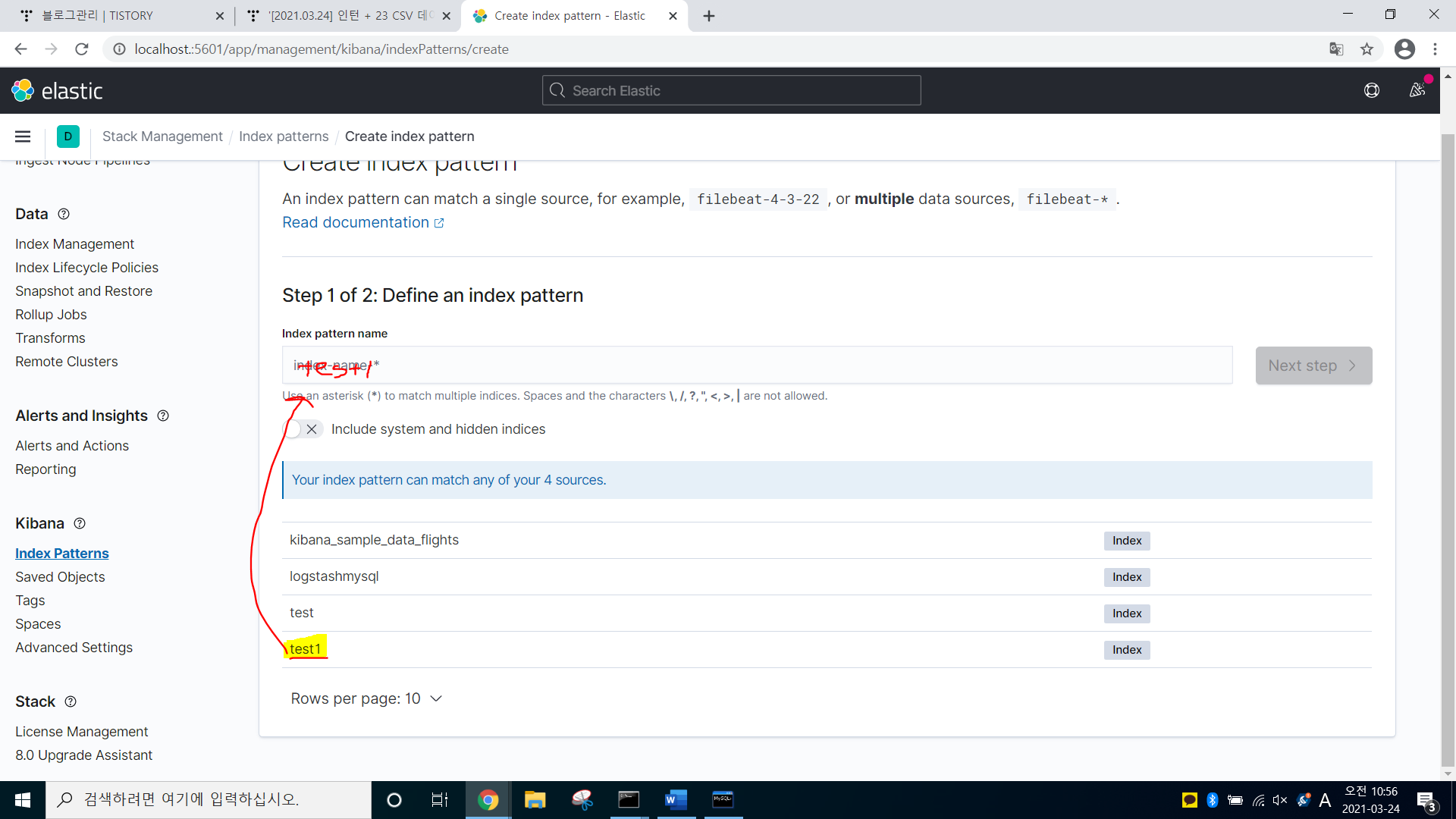
-> 아까 최종으로 만든 test.conf에서 index명을 test1로 줬기 때문에 test1이 최종본이다
-> test1 그대로 쳐준다
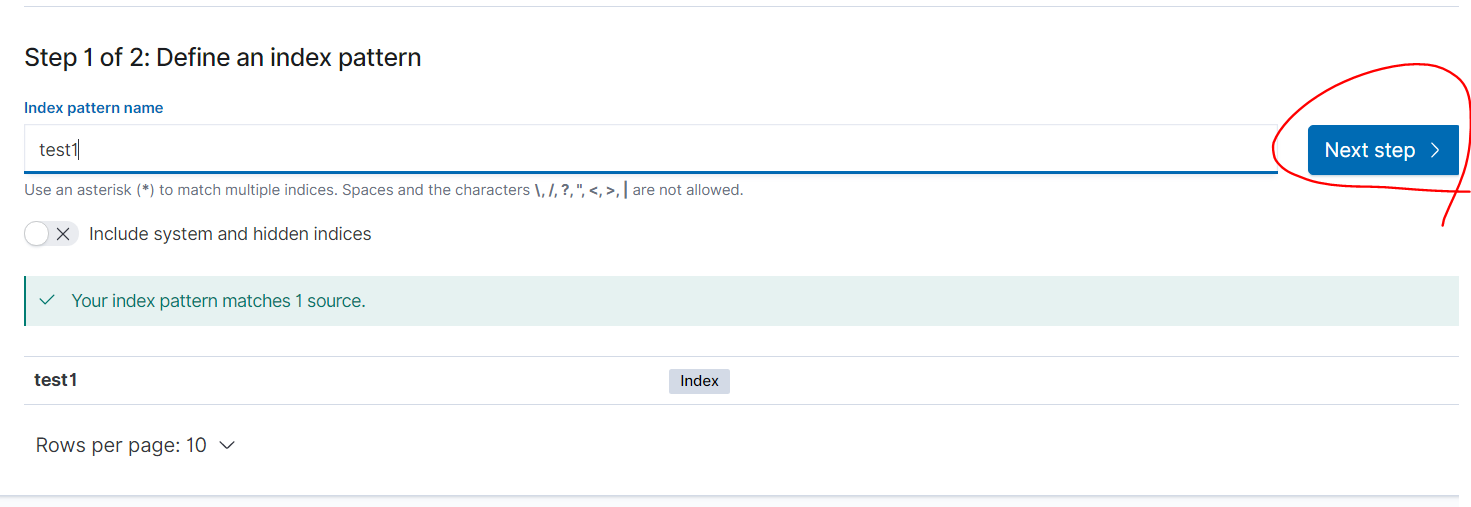
-> Next Step 클릭 -> Create index 클릭
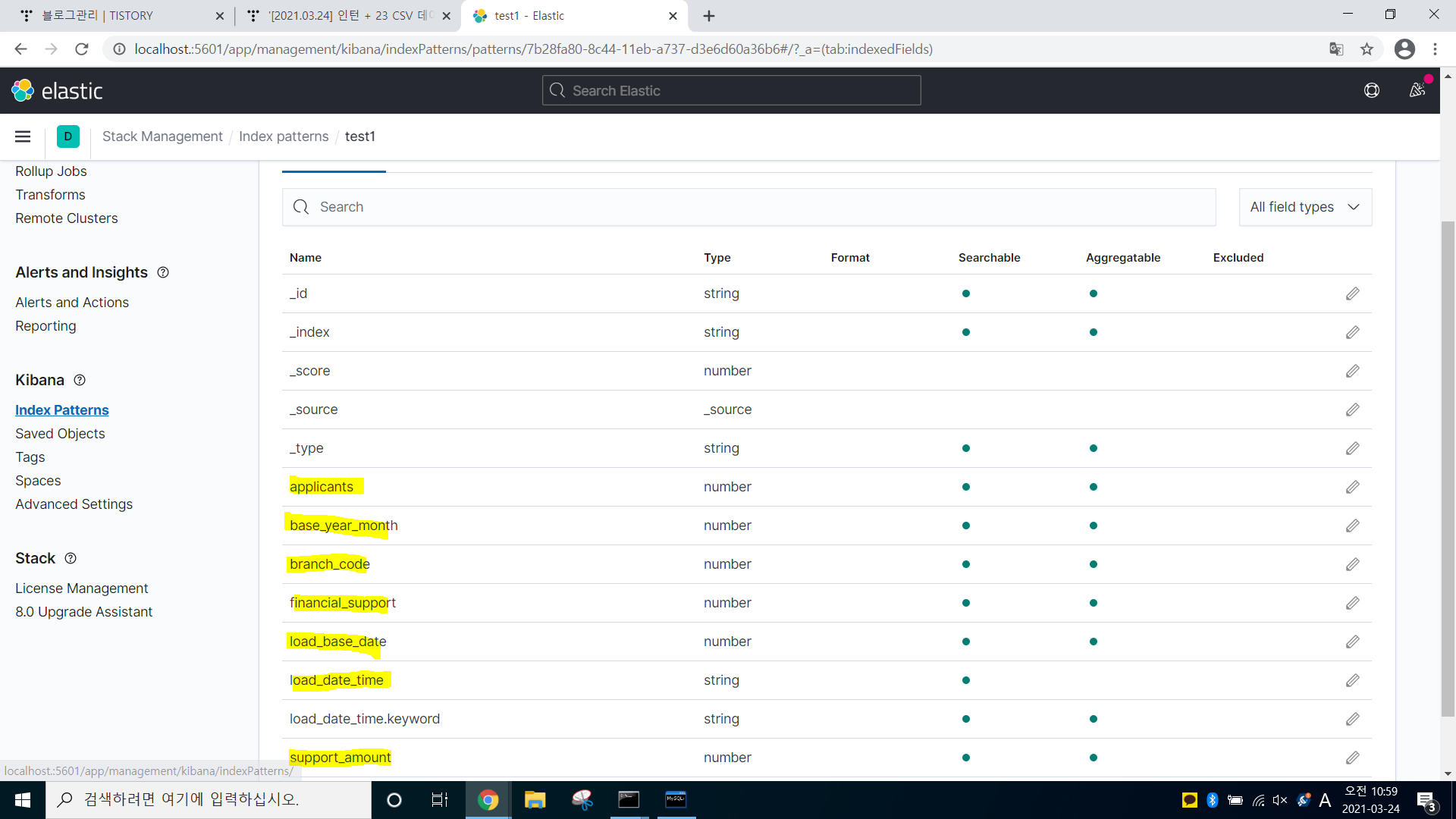
-> .csv 파일로 sql이 잘 연동된 것을 볼 수 있다.
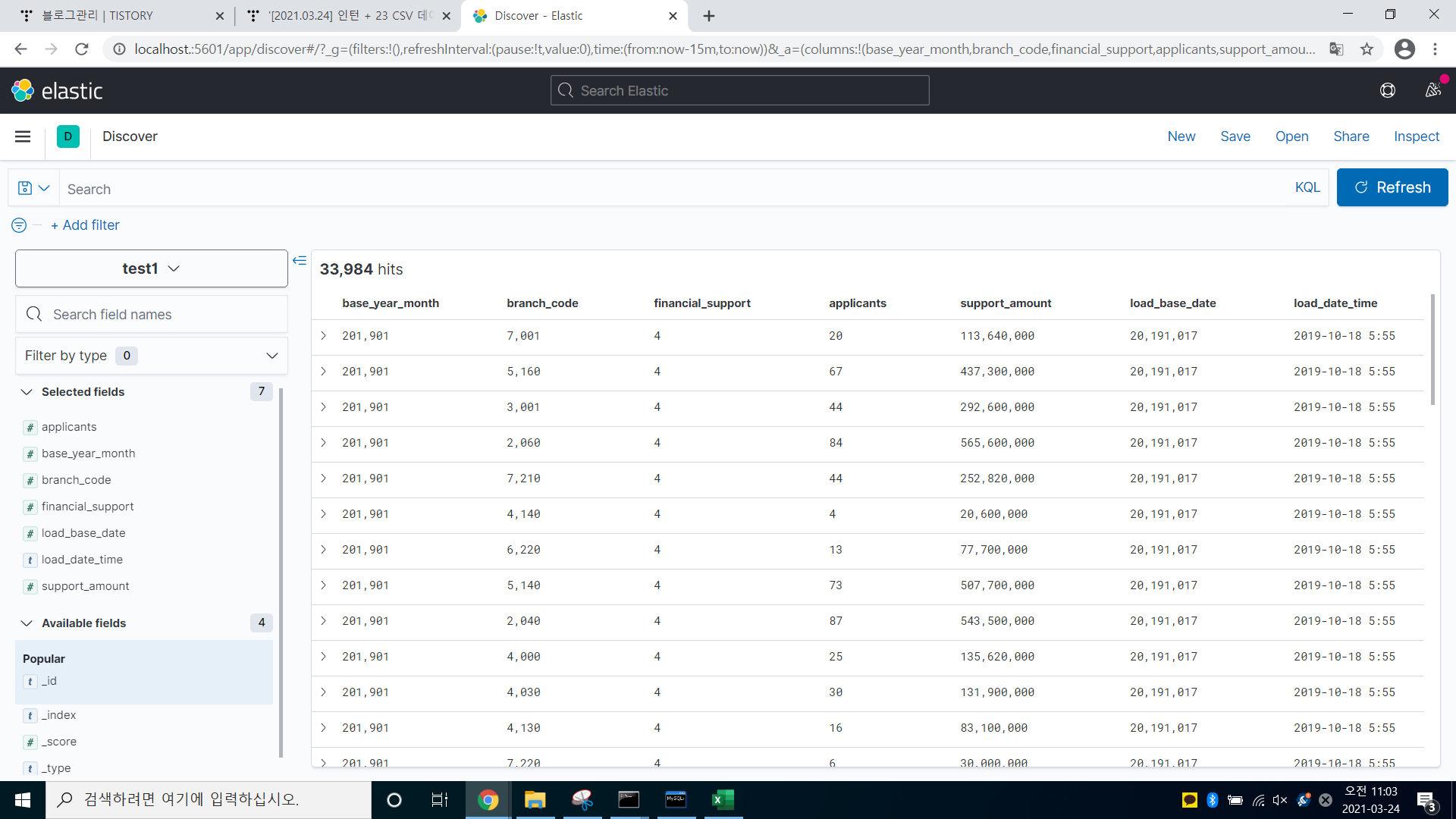
-> discover에 들어가서, 속성 필드 값을 +하여, 원하는 값만 이렇게 출력하게 할 수 있다
-> 엑셀 파일과 속성을 똑같이 넣어, 값이 정확하게 제대로 들어갔다
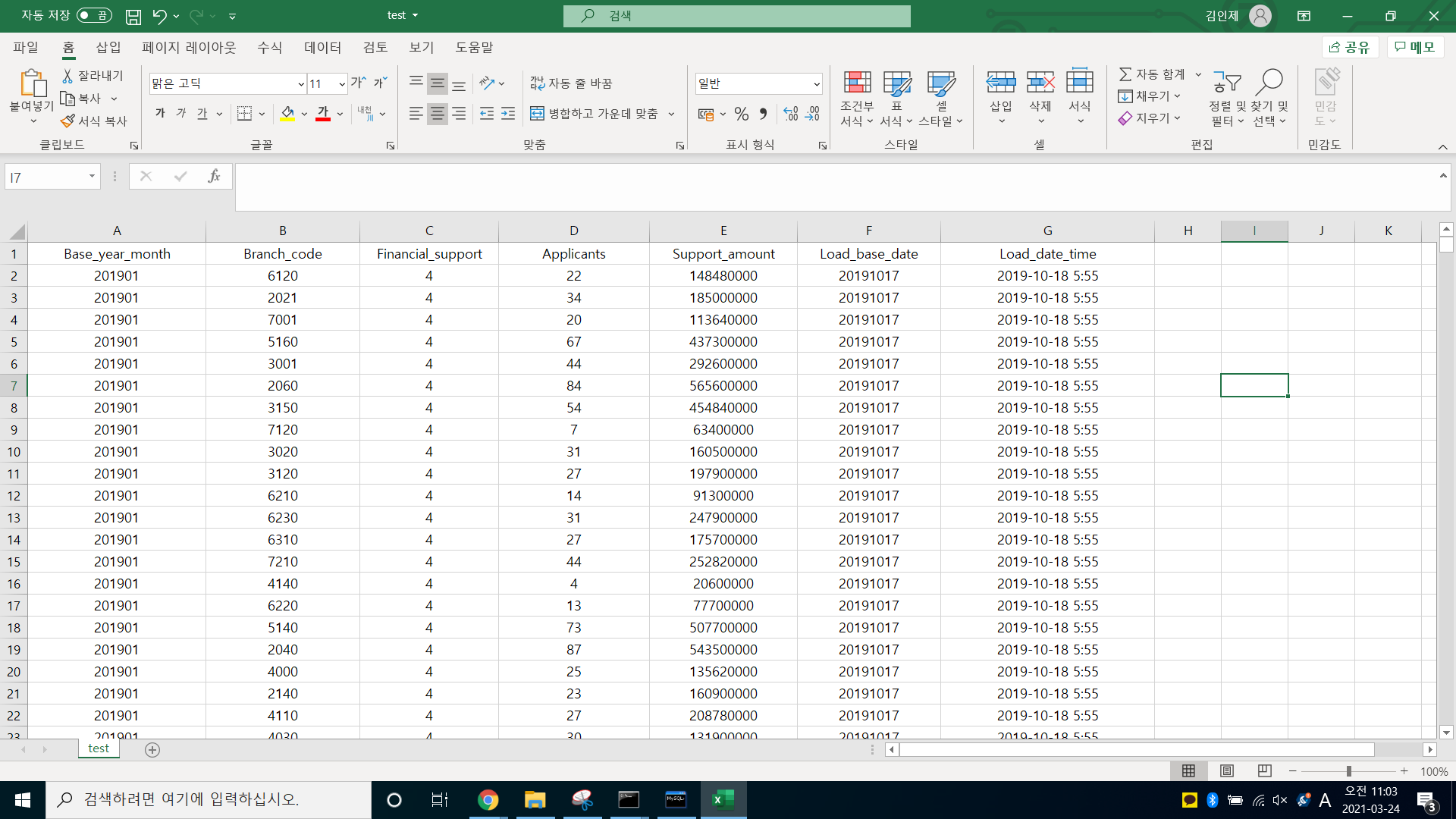
-> 엑셀 파일, logstash와 들어간 값이 동일한 것을 알 수 있다.
-------------------------------------------------------------------------------------------------------------------
이제, 시각화해보자
-> search (Visualizations) -> Create visualization 클릭
-> search (Visualizations) -> Create visualization -> Aggregation based 클릭
-> 내가 하고 싶은 것으로 시각화
kibana로 시각화 하기(1~4 순서)
1. visuallize (표 이름: Metric)
-> savename : test1- count
파일 명 : test1 - count (Metric)
2. visuallize (표 이름 : pie)
Metrics -> Slice size Count(count로 숫자)
Buckets -> Split slices (도넛을 분할)
Aggreation -> Range(범위를 많이 쓰임)
0 < 1500
1500 < 4000
4000 < 7000
7000 < 10000
10000 < 17000
17000 < 31000
31000 < 50000
7개 정도 지정했으며, 이렇게 분할해야 눈에 잘 보인다.
Filed(어떤 속성으로 할 것인지?)
* Sub aggregation -> Significant Terms (파이에서 sub로 또 추가 가능하다. 밑에 ADD)
파일 명 : test1 - branch code(pie)
3. Dashboard
-> Create Dashboard -> Add from library(visualize에서 저장한 것을 가져옴 - test1-count, test1- brach code, flights 가져옴)
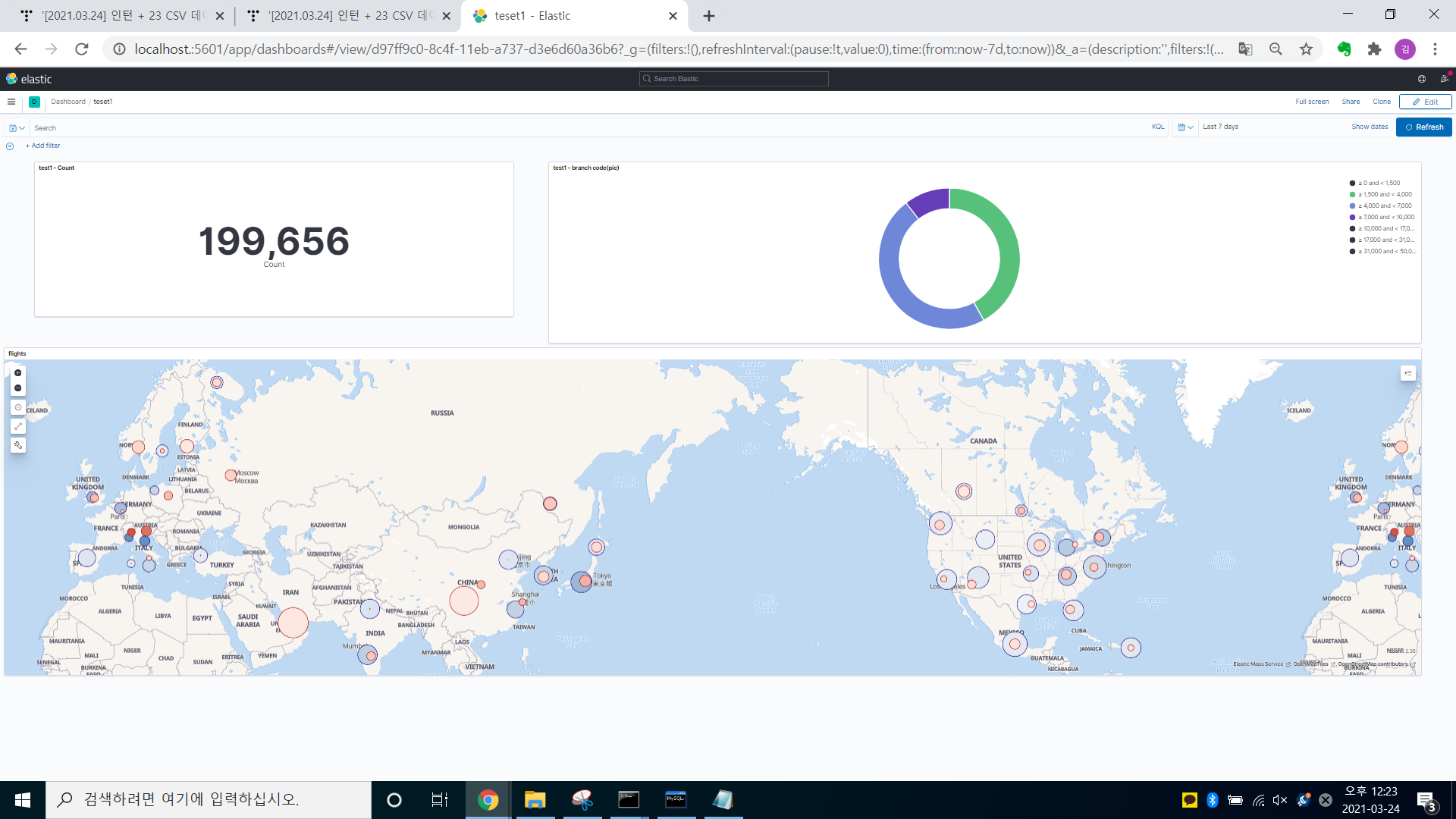
'Data > ELK' 카테고리의 다른 글
| [2021.03.26] 인턴 +25 logstash filter 기능(사용법) (0) | 2021.03.26 |
|---|---|
| [2021.03.24] 인턴 + 23 파일 비트란?(설치 및 실습 포함) (0) | 2021.03.24 |
| [2021.03.23] 인턴 + 22 MySQL Workbench 설치 방법 및 csv파일을 DB에 저장하는 방법?(+Editplus, 공공데이터 csv 파일 다운 방법) (0) | 2021.03.23 |
| [2021.03.23] 인턴 + 22 logstash & mysql 연동 (0) | 2021.03.23 |
| [2021.03.22] 인턴 + 21 일래스틱서치(ELK) 설치 (0) | 2021.03.22 |



댓글