[2021.07.01] 인턴 +122 How to Use Crawling in AWS Lambda with Selenium Module?
https://docs.aws.amazon.com/lambda/latest/dg/welcome.html
What is AWS Lambda? - AWS Lambda
In the AWS Lambda Developer Guide, we assume that you have experience with coding, compiling, and deploying programs using one of the supported languages.
docs.aws.amazon.com
-> aws lambda document
AWS 클라우드 공부를 약 2주정도 시간을 투자하여, 내가 알아낸 방법들이다.
* AWS Lambda 사용법
* Layer 사용법
* IAM User 만드는법 (권한주는법, 자격증명생성 방법)
* VS code 에서 AWS Toolkit을 통하여 연결하는 방법
* AWS Lambda 에서 webdriver(Selenium)을 사용하는 방법
# ★★★★★ AWS Lambda 에서 Webdriver를 사용하기 위한 코드 ★★★★★
-> 클라우드에서는 webdriver를 사용하려면, 꼭 headless를 사용해야함
-> 아래 코드를 복붙해서 사용하면 됨
def get_driver():
try:
options = Options()
options.binary_location = '/opt/headless-chromium' # /opt 경로는 해당 aws lambda에서, layer에 추가 했을 때, 나오는 초기 경로임
options.add_argument('lang=en') # 언어를 en(영어로)
# cloud 에서 사용하기 위한, webdriver - headless
options.add_argument('--headless') # 창이 뜨지 않게 설정
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--window-size=1500,1000") # 창 사이즈 옵션 조절 -> 그러나 headless에선 필요 없는 코드
# fake-user-agent를 추가
options.add_argument(
'user-agent=Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36')
# options.add_argument('lang=en') 와 같이 써줘야함. (바인딩 언어 옵션)
options.add_experimental_option('prefs', {'intl.accept_languages': 'en,en_US'})
# ★★★★★ webdriver를 실행, /opt 경로는 해당 aws lambda에서, layer에 추가 한 후 접근해주는 경로임 ★★★★★
driver = webdriver.Chrome('/opt/chromedriver', chrome_options=options)
return driver
except Exception as e:
return e
-------------------------------------------------------------------------------------------------------------------------------
aws lambda 에서 유튜버 구독자 링크를 크롤링한 Full Code
import json
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def get_driver():
try:
options = Options()
options.binary_location = '/opt/headless-chromium' # /opt 경로는 해당 aws lambda에서, layer에 추가 했을 때, 나오는 초기 경로임
options.add_argument('lang=en') # 언어를 en(영어로)
# cloud 에서 사용하기 위한, webdriver - headless
options.add_argument('--headless') # 창이 뜨지 않게 설정
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--window-size=1500,1000") # 창 사이즈 옵션 조절 -> 그러나 headless에선 필요 없는 코드
# fake-user-agent를 추가
options.add_argument(
'user-agent=Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36')
# options.add_argument('lang=en') 와 같이 써줘야함. (바인딩 언어 옵션)
options.add_experimental_option('prefs', {'intl.accept_languages': 'en,en_US'})
# ★★★★★ webdriver를 실행, /opt 경로는 해당 aws lambda에서, layer에 추가 한 후 접근해주는 경로임 ★★★★★
driver = webdriver.Chrome('/opt/chromedriver', chrome_options=options)
return driver
except Exception as e:
return e
# 문자열을 숫자로 변환하는 함수
def string_to_number(text):
# text 가 없다면 0을 반환
if text is None or len(text) == 0:
return 0
try:
num_change = 1
word = ''
# M이라는 단어가 text에 있다면, unit에 1000000을 선언
if 'M' in text:
num_change = 1000000
word = 'M'
elif 'K' in text:
num_change = 1000
word = 'K'
elif 'B' in text:
num_change = 1000000000
word = 'B'
# 콤마,subscribers,subscriber,views,view,videos,video,Verified 삭제
text = text.replace(',', '')
text = text.replace('subscribers', '')
text = text.replace('subscriber', '')
text = text.replace('views', '')
text = text.replace('view', '')
text = text.replace('videos', '')
text = text.replace('video', '')
text = text.replace('Verified', '')
# 위에서 삭제한 text의 양옆 공백 제거후, 단어(K,M,B) 삭제 후 변환한 숫자 단위로 곱해줌
number = float(text.strip().replace(word, '')) * num_change
number = int(number)
return number
except Exception as e:
print('string to convert error : ', text)
return e
# BeautifulSoup에는 select 와 select_one 메서드가 존재한다.
# select -> 결과값이 리스트로 저장 / select_one -> 문서의 처음부터 찾게 되며 가장 첫 <a> 태그를 호출
# select_one의 경우 바로 변수명.text , 변수명["href"]를 통해 속성 값 추출 가능
# https://velog.io/@bangsy/python-crawling-%EC%9D%B4%EB%AF%B8%EC%A7%80-%ED%81%AC%EB%A1%A4%EB%A7%81
# 유튜브 - 링크 추출 (image 썸네일)
def get_img_thumbnail(result):
img_thumbnail = None # 비어있음으로 초기화
try:
img_thumbnail = 'https:' + result.select_one('img#img').get('src') # https: 의 가장 첫문서에서, img#img 태그에 src 부분을 추출
except Exception as e:
return img_thumbnail
# 유튜브 - 비디오 조회수
def get_video_count(result):
try:
video_count = result.select_one('span#video-count').text # span#video-count 태그에서 text를 추출함
video_count = string_to_number(video_count) # 추출한 문자열을 정수로 변환
return video_count
except Exception as e:
print('video count error', e)
return 0
# 유튜브 - 구독자 수
def get_subscriber(result):
try:
subs_count = result.select_one('span#subscribers').text # span#subscribers 태그에서 text를 추출함
subs_count = string_to_number(subs_count)
return subs_count
except Exception as e:
print('sub count error', e)
return 0
# AWS - lambda_hander fucntion(event,context)
def lambda_handler(event, context):
query = '드레이븐' # 지정한 사이트에서 search할 검색 단어
base_url = 'https://www.youtube.com' # 유튜브로 지정
start_time = time.time() # 시작시간 출력
# event에서 queryStringParameters가 있다면, 새로운 변수(query_string_parameters)에 넣어줌
if event.get('queryStringParameters'):
query_string_parameters = event.get('queryStringParameters')
# query_string_parameters태그에서, get 메서드를 통해, query 부분을 추출후 query에 저장
if query_string_parameters:
query = event.get('queryStringParameters').get('query')
# 아래의 링크는 query에 의해 해당 관련 유튜버 들이 검색됨
# ex) 드레이븐, 롤, elastic입력 했을 때 관련된 영상이 아닌 유튜버가 검색됨
url = f'https://www.youtube.com/results?search_query={query}&sp=EgIQAg%253D%253D'
driver = get_driver()
try:
driver.get(url) # 검색한 화장품 유튜버 추출
time.sleep(3)
html = driver.page_source # driver.page_source는 해당 페이지에의 소스코드보기를 가져온 것임
# 해당 페이지에서 F12(개발자모드)를 통해 추출하려고 하는 태그를 살펴봄
bs = BeautifulSoup(html, 'html.parser')
search_sections = bs.select_one('div#contents.style-scope.ytd-section-list-renderer')
pv = search_sections.select_one('ytd-search-pyv-renderer')
search_result = bs.select('ytd-channel-renderer')
count = 0
print('size - ', len(search_result), '\n')
channel_items = []
for result in search_result:
try:
channel_link = base_url + result.select_one('a.ytd-channel-renderer').get('href')
channel_title = result.select_one('#text.ytd-channel-name').text
subs_count = get_subscriber(result)
video_count = get_video_count(result)
img_thumbnail = get_img_thumbnail(result)
# print(channel_link, channel_title, subs_count, video_count, img_thumbnail)
# print(count, channel_link, channel_title, subs_count, video_count, img_thumbnail)
# dict를 선언하여, 사전에 링크,제목주소,구독자수,비디오수 넣어줌
# 1 {'link': 'https://www.youtube.com/channel/UCqrNqg3UgVoD3Sa-F_TxuSA', 'title': '디렉터 파이', 'subscriber_count': 904000, 'video_count': 253, 'channel_id': 'UCqrNqg3UgVoD3Sa-F_TxuSA'}
channel = {}
channel['link'] = channel_link
channel['title'] = channel_title
channel['subscriber_count'] = subs_count
channel['video_count'] = video_count
# 유튜브 링크 주소에 channel이 있다면 /로 구분지어서 4번째 것을 저장함
if 'channel' in channel_link:
channel['channel_id'] = channel_link.split('/')[4]
if 'user' in channel_link:
channel['username'] = channel_link.split('/')[4]
if img_thumbnail:
channel['thumbnail_url'] = img_thumbnail
channel_items.append(channel)
print(count, channel)
count += 1
except Exception as e:
print(count, e)
count += 1
# 끝나는 시간은 현재시간(time.time() - 앞에서 시작한 시간을 뺌)
end_time = time.time() - start_time
print('channel item size', len(channel_items))
print('elapsed time', end_time)
# webdriver 창 종료
driver.close()
driver.quit()
items = json.dumps(channel_items, ensure_ascii=False)
body = {
"message": "succeed",
"items": items
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return response
# 실패 했을 때, 예외처리로 webdriver 종료후 , 에러 문구 출력
except Exception as e:
print(e)
driver.close()
driver.quit()
body = {
"message": "fail",
"items": []
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return response
<출력 결과>
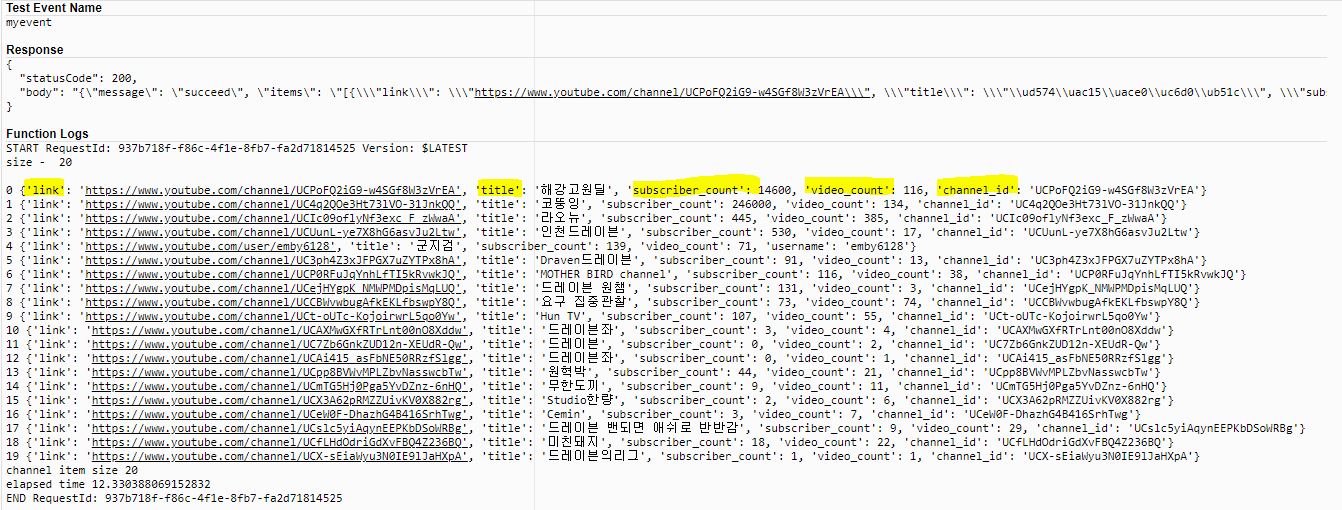
-----------------------------------------------------------------------------------------------------------------------
+@ 직렬화 (정확히 어떤 의미로 쓰이는진 모름, 참고용)
-> 데이터를 보내기 위해서 바이트 코드로 변환
* refer : https://stackoverflow.com/questions/1960516/python-json-serialize-a-decimal-object
import decimal
class DecimalEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, decimal.Decimal):
return int(obj)
return super(DecimalEncoder, self).default(obj)
'Data > Crawling' 카테고리의 다른 글
| [2021.07.06~14] 인턴 +127 특정 사이트(?-talk) crawling 실습7 in 로컬 PC (0) | 2021.07.06 |
|---|---|
| [2021.07.05] 인턴 +126 How to add data to AWS DB (in Python)? (0) | 2021.07.05 |
| [2021.06.29] 인턴 +120 How to create user-agent in python? (0) | 2021.06.29 |
| [2021.05.12] 인턴 +72 CSV 파일을 읽어오는 방법 (일부분 값 추출 방법도 포함) (0) | 2021.05.12 |
| [2021.05.11] 인턴 +71 (최종) - 저장된 CSV 데이터를 읽어서, 인플루언서 업데이트 비교(리팩토링O, 조건1-3 포함) (0) | 2021.05.11 |



댓글